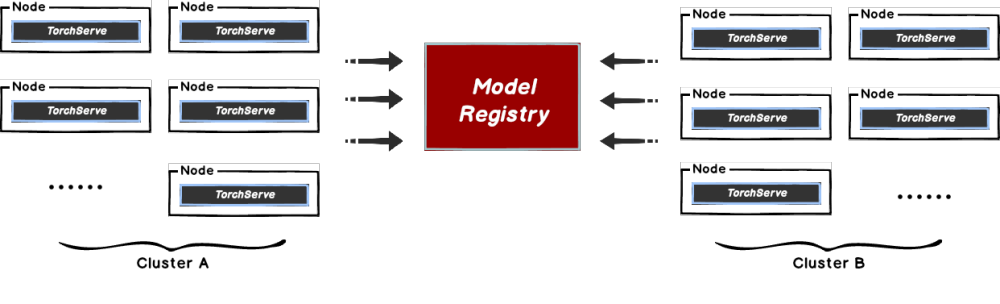
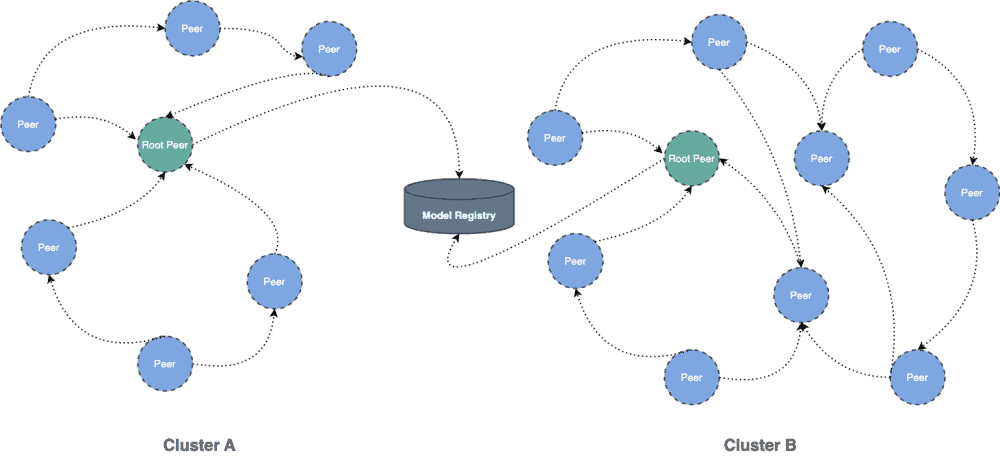
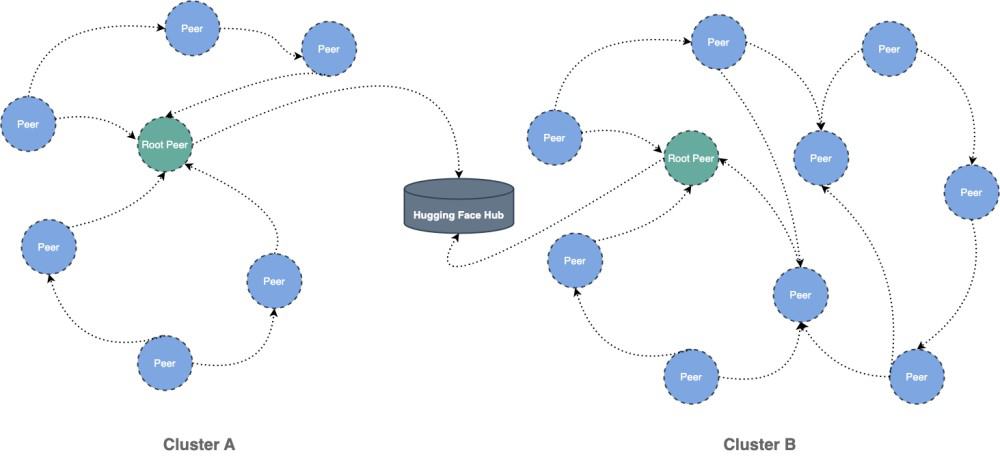
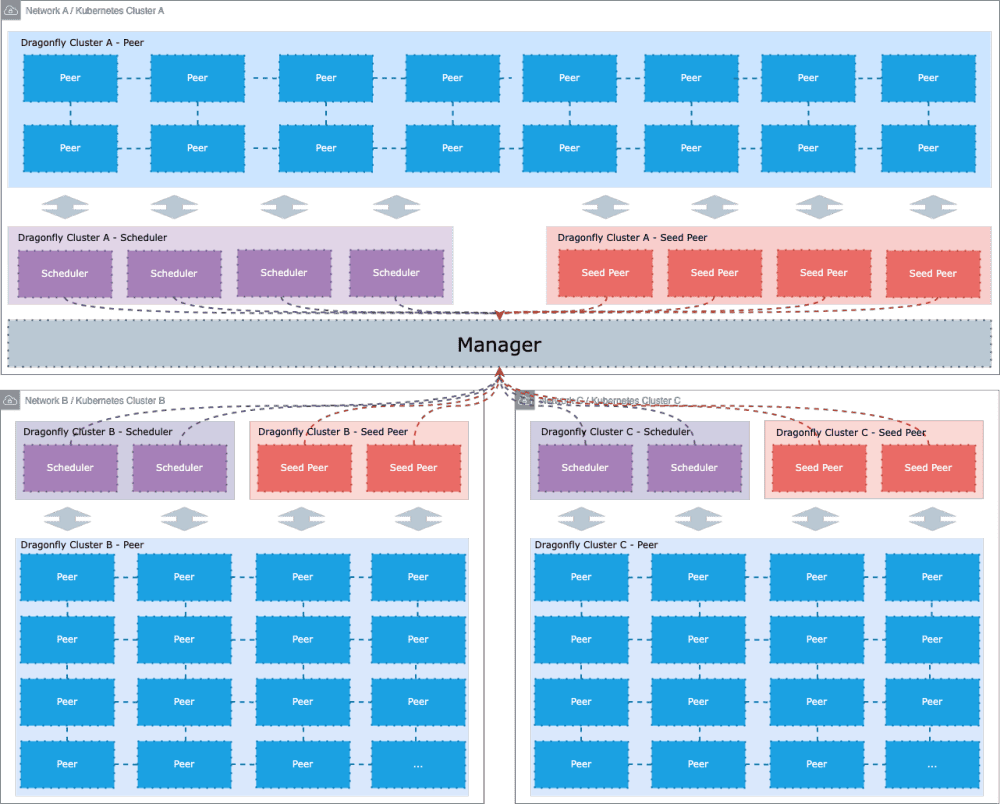
CNCF projects highlighted in this post, and migrated by mingcheng.
Introduction
ZOLOZ is a global security and risk management platform under Ant Group. Through biometric, big data analysis, and artificial intelligence technologies, ZOLOZ provides safe and convenient security and risk management solutions for users and institutions. ZOLOZ has provided security and risk management technology support for more than 70 partners in 14 countries and regions, including China, Indonesia, Malaysia, and the Philippines. It has already covered areas such as finance, insurance, securities, credit, telecommunications, and public services, and has served over 1.2 billion users.
With the explosion of Kubernetes and cloud-native, ZOLOZ applications have begun to be deployed on a large scale on public clouds using containerization. The images of ZOLOZ applications have been maintained and updated for a long time, and both the number of layers and the overall size have reached a large scale (hundreds of MBs or several GBs). In particular, the basic image size of ZOLOZ’s AI algorithm inference application is much larger than that of general application images (PyTorch/PyTorch:1.13.1-CUDA 11.6-cuDNN 8-Runtime on Docker Hub is 4.92GB, compared to CentOS:latest with only about 234MB).
For container cold start, i.e., when there is no image locally, the image needs to be downloaded from the registry before creating the container. In the production environment, container cold start often takes several minutes, and as the scale increases, the registry may be unable to download images quickly due to network congestion within the cluster. Such large images have brought many challenges to application updates and scaling. With the continuous promotion of containerization on public clouds, ZOLOZ applications mainly face three challenges:
- The algorithm image is large, and pushing it to the cloud image repository takes a long time. During the development process, when testing in the testing environment, developers often hope to iterate quickly and verify quickly. However, every time a branch is modified and released for verification, it takes several tens of minutes, which is very inefficient.
- Pulling the algorithm image takes a long time, and pulling many image files during cluster expansion can easily cause the cluster network card to be flooded and affect the normal operation of the business.
- The cluster machine takes a long time to start up, making it difficult to meet the needs of sudden traffic increases and elastic automatic scaling.
Although various compromise solutions have been attempted, these solutions all have their shortcomings. Now, in collaboration with multiple technical teams such as Ant Group, Alibaba Cloud, and ByteDance, a more universal solution on public clouds has been developed, which has low transformation costs and good performance, and currently appears to be an ideal solution.